HDP 数据处理
同步任务类型
HDP 平台的数据处理支持手动同步、定时同步和实时同步三种方式,可满足不同场景需求。一般来说,用户只需配置简单的字段映射规则,就能实现数据库与工作表之间的数据同步。下面分别说明三种同步类型的机制和适用场景:
-
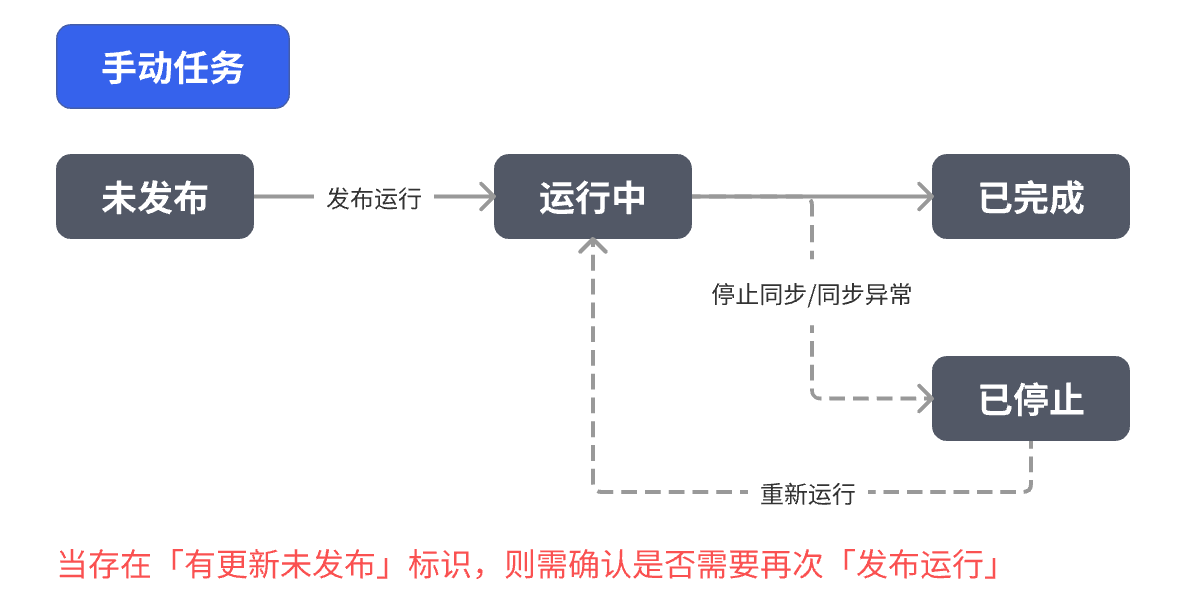
手动同步: 由用户手动触发执行的同步。创建任务后,只有在用户点击“发布运行”或“发布”按钮时,系统才会启动数据同步过程。适用于一次性或临时的数据迁移和测试场景,例如将旧系统数据批量导入平台或对数据更新进行验证等。在手动同步中,每次都需要用户主动启动任务,系统并不会自动运行。
-
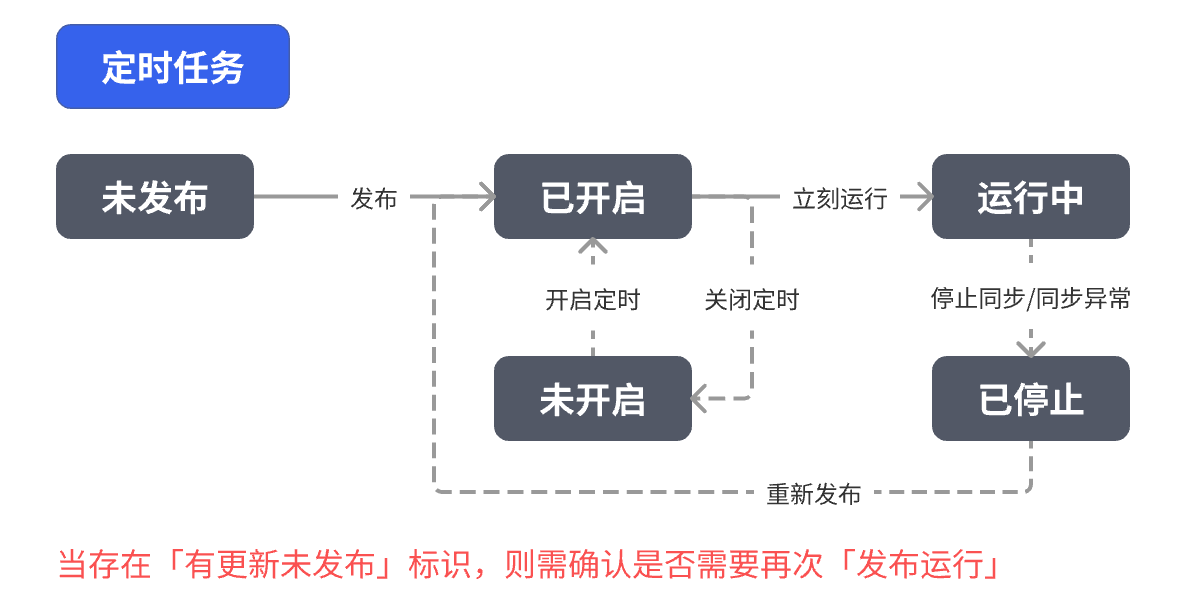
定时同步: 按照预先设定的时间计划自动运行的同步。用户可以在任务创建后点击“开启定时”按钮,根据提示设置同步频率(比如每小时执行一次,或每天固定时间执行)。设定好后,系统会在指定时间自动启动任务,无需人工干预。适用于需要周期性更新的数据场景,比如每天凌晨同步新订单数据或每小时同步销售数据等。
-
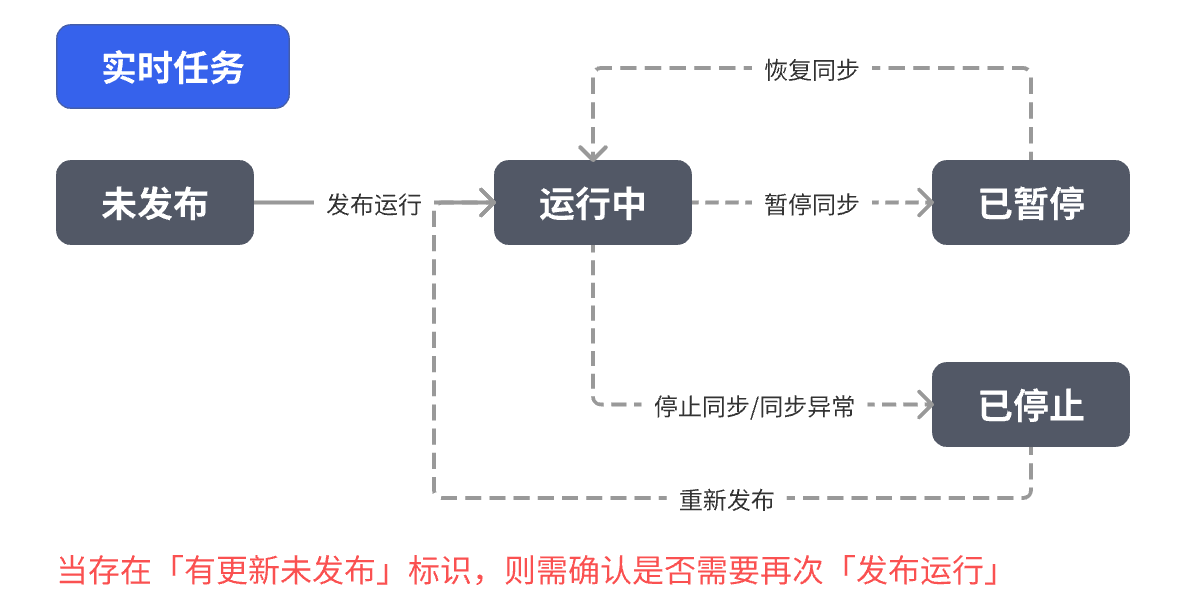
实时同步: 数据源一旦发生变化,系统就会尽快同步更新,无需等待定时调度。实时同步方式能够保证数据几乎同步更新,适合对时效性要求高的场景,例如自动将业务系统中新增或修改的记录及时同步到数据仓库或工作表中。 通过选择不同类型的同步任务,用户可以针对具体需求选择合适的模式。
不同任务类型支持的数据源类型:
| 手动同步 | 定时同步 | 实时同步(CDC) | |
|---|---|---|---|
| 作为源 | 不支持:SAP HANA、Kafka、HAP工作表 | 不支持:Kafka、HAP工作表 | 不支持:SAP HANA |
| 作为目的地 | 不支持:Oracle、SAP HANA | 不支持:Oracle、SAP HANA | 不支持:Oracle、SAP HANA |
同步任务创建&发布
1.进入同步任务界面
在平台首页依次点击左侧导航【同步任务】> 【数据处�理】,进入同步任务列表页。该页面会显示所有已创建的同步任务,可一目了然地看到每个任务的来源和目的地类型。
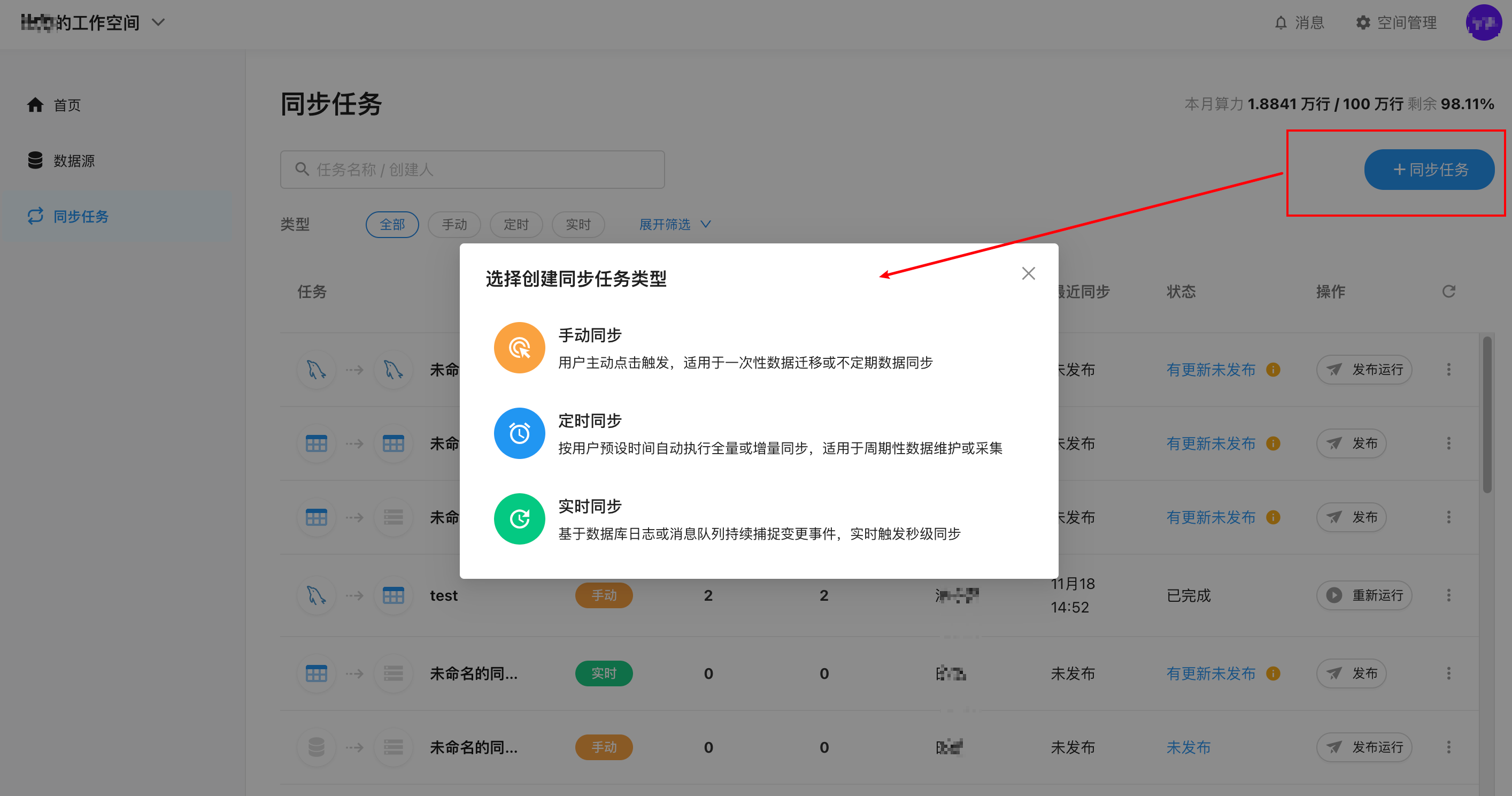
2.新建任务并选择任务类型
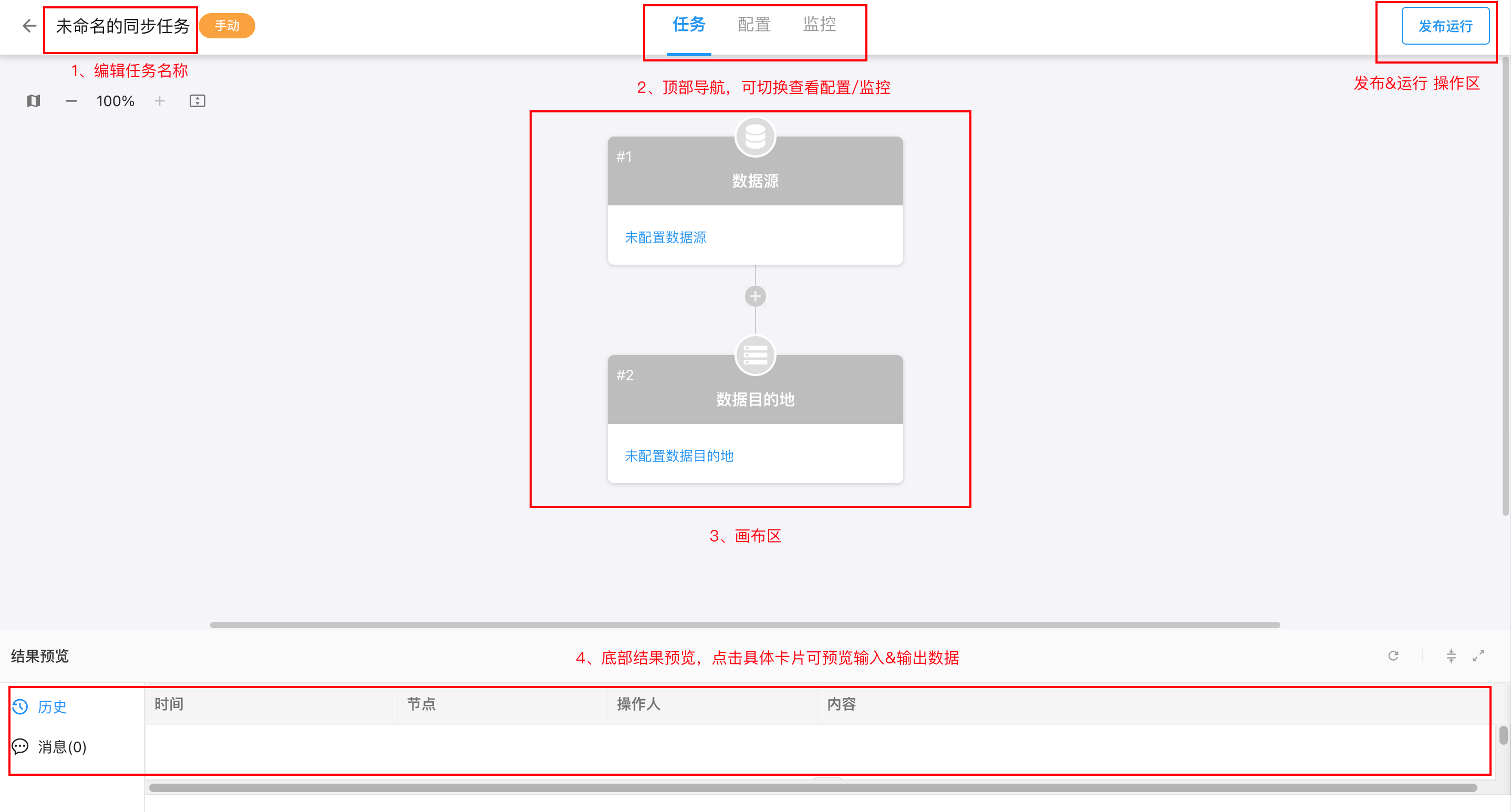
点击页面上的「+同步任务」按钮,弹出选择类型弹窗,选择一种任务类型,该任务的详细配置界面,也称为任务画布,以下为界面逐区说明:
-
顶部标题区
▪ 任务名称(如:未命名的同步任务)
▪ 同步类型(如:手动 / 定时 / 实时)
-
顶部页签(任务 / 配置 / 监控)
▪ 任务:当前页面,查看任务结构、数据源配置、结果预览、历史记录等
▪ 配置:设置同步逻辑、字段映射、调度配置(实时/定时任务才会出现相关内容)
▪ 监控:查看同步运行状态、读写行数、任务日志等监控数据
-
顶部操作按钮区
▪ 根据不同的发布&运行状态,展示不同按钮
-
画布区(流程结构显示)
▪ 数据源:点击后于右侧抽屉区配置数据源
▪ 数据目的地:点击后于右侧抽屉区配置数据目的地
▪ 「+」:点击后于右侧抽屉区添加数据处理动作
-
结果预览区
当未选择具体卡片时,显示以下内容:
-
历史:显示该任务执行过的同步记录每次的时间、节点、操作人、内容
-
消息:同步时系统产出的提示信息
当选择具体卡片时,显示该卡片输入(最新)&输出(快照)数据
-
3.配置数据源
进入任务画布后,在页面左侧点击「数据源」卡片。右侧会展开数据源配置面板,包括可搜索的数据源列表。点击查看 不同任务类型支持的数据源类型。
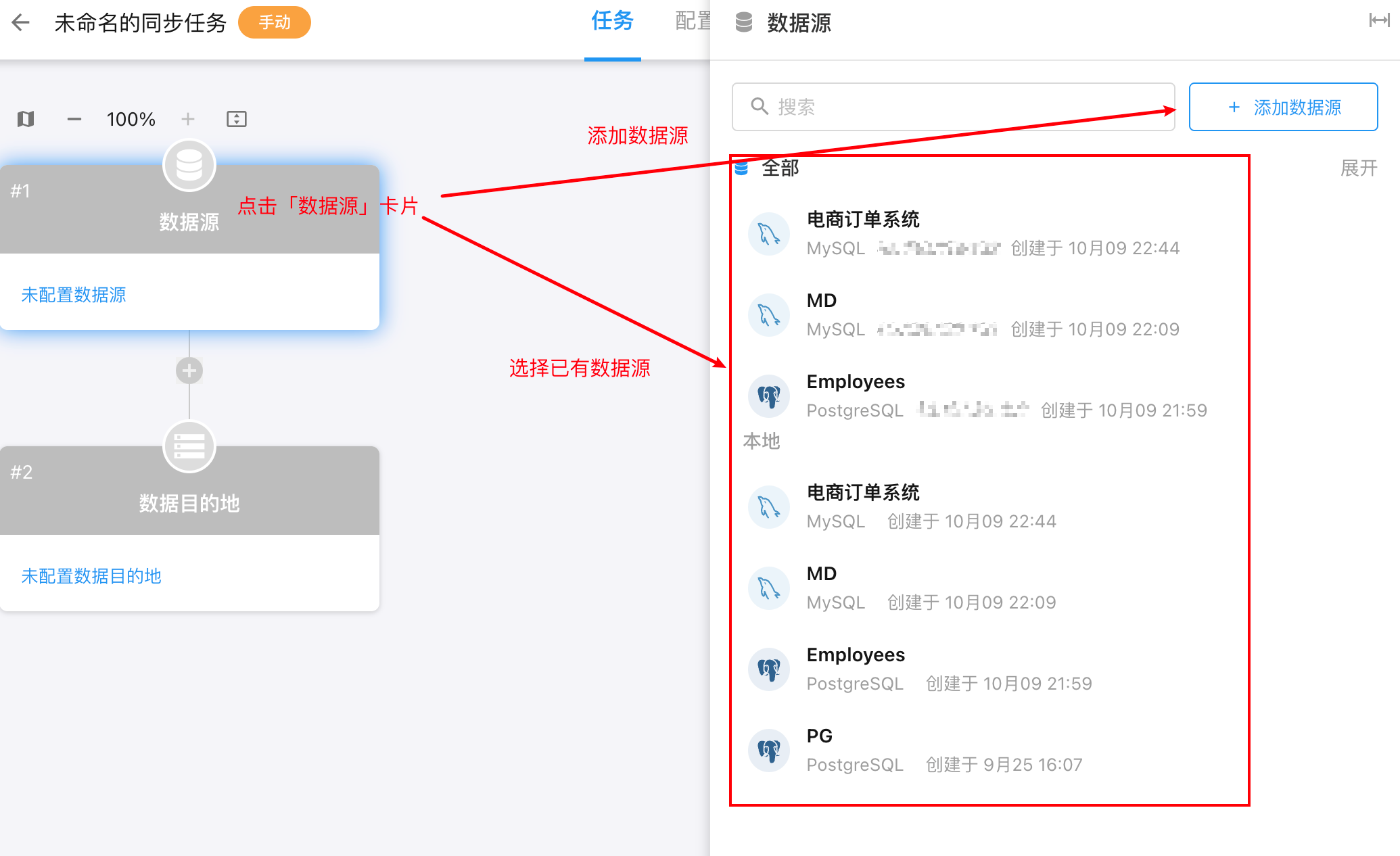
1)可选择已有数据源,或添加数据源,数据源添加方式同创建数据源
2)继续选择数据库&schema(选)&数据表,系统会在卡片上显示已选中的数据源名称与表名。
3)勾选需读取的字段,可重命名字段名称;点击查看字段同步规则
4)点击保存,同步至所选「数据源」卡片
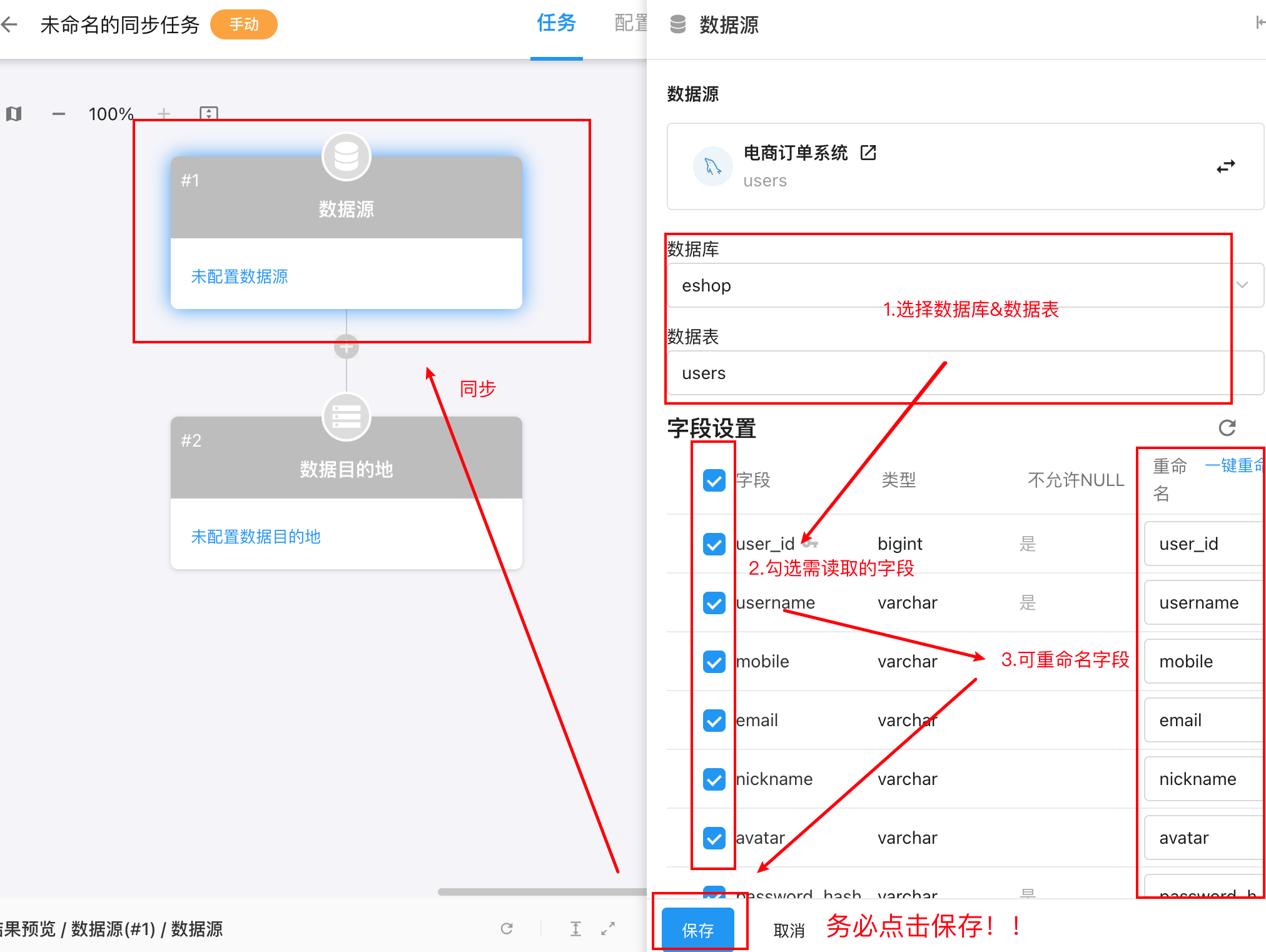
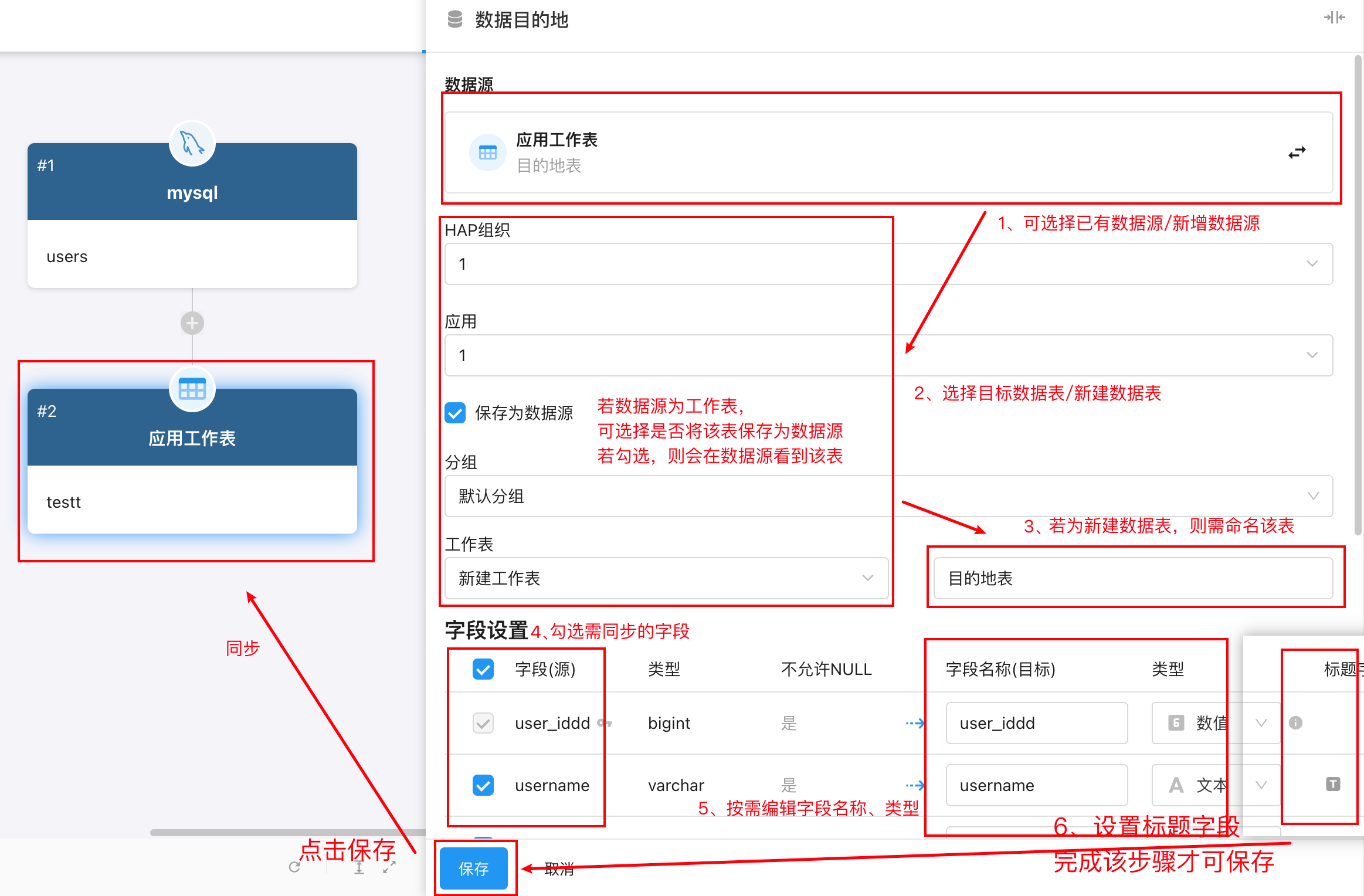
4.配置数据目的地
在页面左侧点击「数据目的地」卡片,右侧会展开数据目的地配置面板,包括可搜索的数据源列表。
1)可选择已有数据源,或添加数据源,数据源添加步骤同创建数据源。
2)继续选择数据库与数据表,系统会在卡片上显示已选中的数据源名称与表名。
3)选择源字段和对应目标字段,完成一一映射,按需编辑字段名称、类型;点击查看字段同步规则。
4)设置标题字段
5)点击保存,同步至所选「数据目的地」卡片
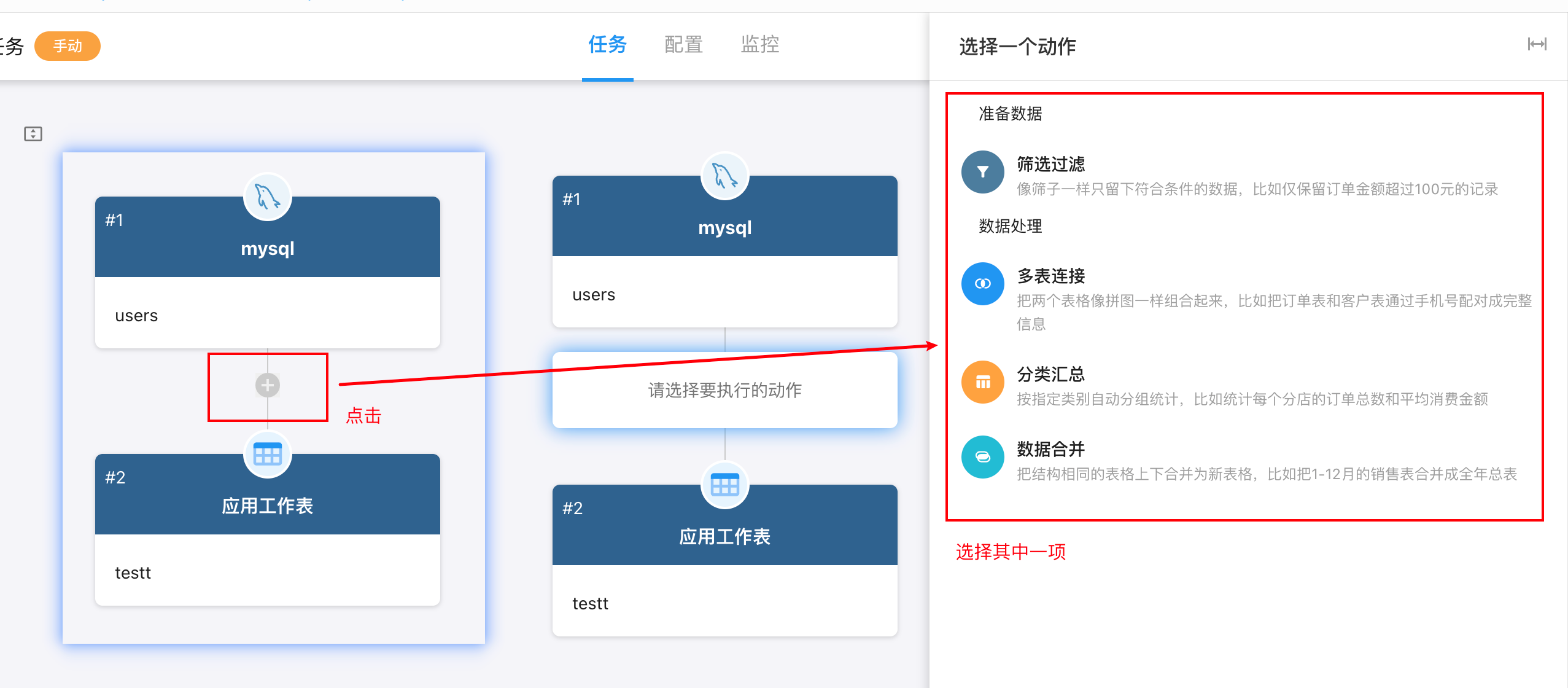
5.添加「数据处理」动作
在任务画布中,数据源与数据目的地之间有「+」,点击即可添加ELT动作,其类型、作用、具体操作方法可跳转至数据处理查看
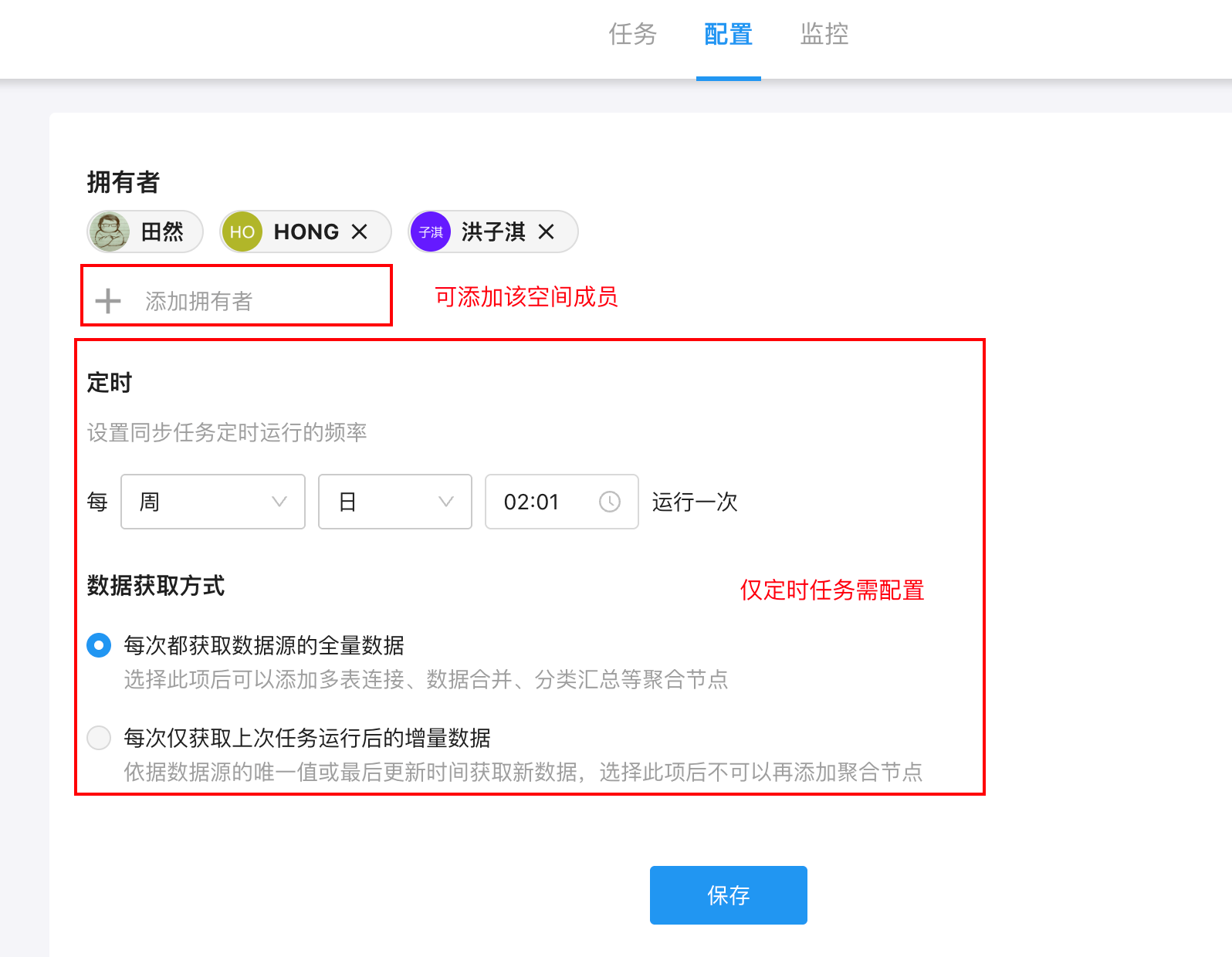
6.配置拥有者、定时与数据获取方式
将任务画布上方的导航切换至「配置」,可设置任务的基础属性,包括:
任务拥有者:任务创建者即为拥有者,空间管理员可查看,如需修改可在此选择空间中的其他成员
定时规则(仅“定时任务”可配置):设定同步时间、周期等执行计划
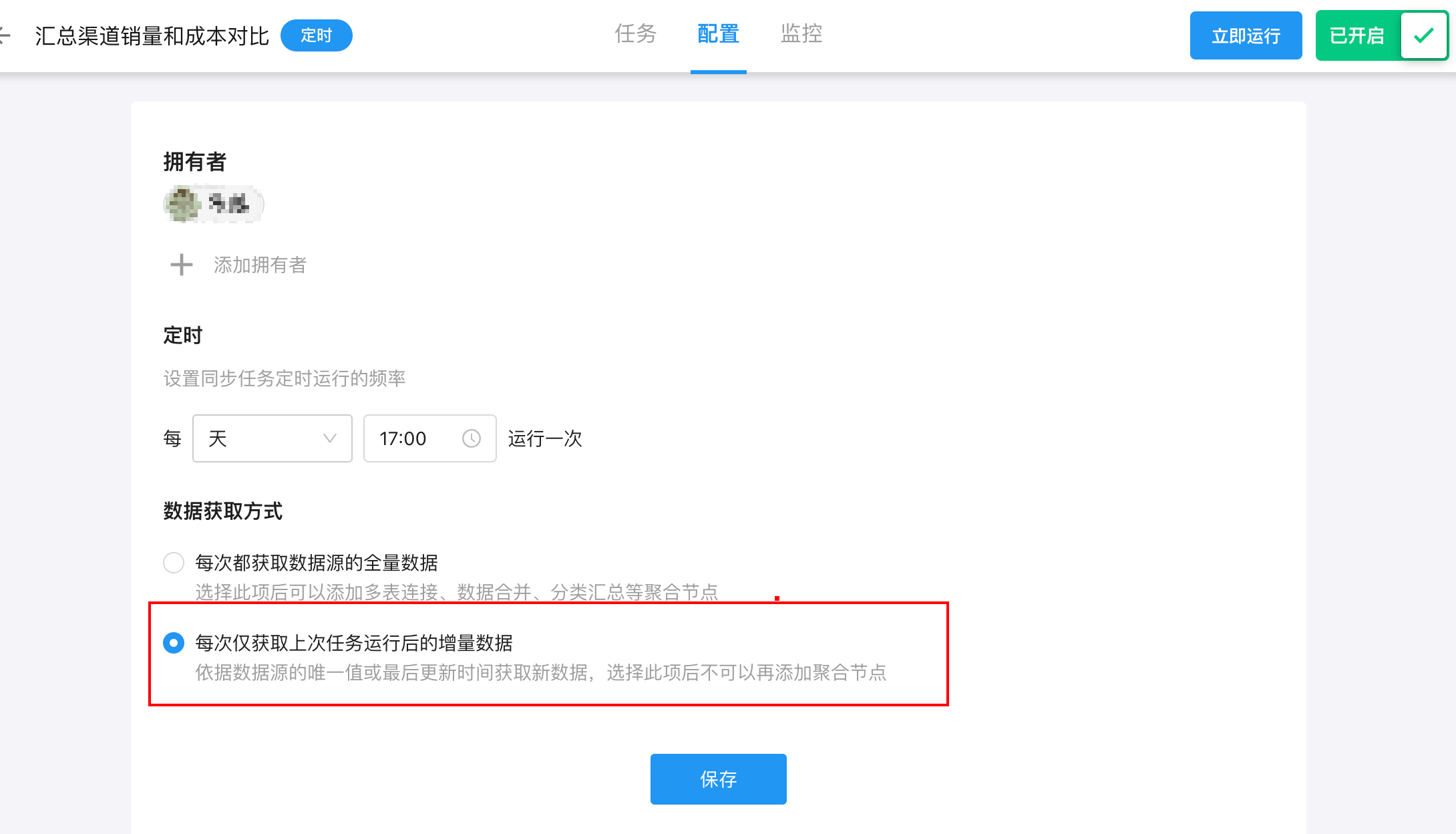
数据获取方式(仅“定时任务”可配置):全量数据/增量数据
-
每次都获取数据源的全量数据: 系统每次运行任务时,都会从数据源获取整张表的所有数据,这种方式适用于:
▪ 多表之间需要进行关联、合并
▪ 需要对所有数据做分类汇总、求和等统计操作
▪ 数据量不大、可以接受全部重新同步
▪ 每次同步都希望得到最完整、最准确的结果
如果您的任务需要做“汇总”“分组”“统计”,请选择此方式。
-
每次仅获取上次任务运行后的增量数据: 系统只会获取上次同步之后新增或被更新的数据(增量部分),不会重新同步完整数据。
这种方式适用于:
-
订单、库存等实时变化的数据
-
数据量较大,不适合每次都跑全量
-
希望加快同步速度、降低对数据库的压力
-
只需要持续同步新增数据,而不是统计全量数据
注意:由于增量数据只是“最新变化的那一部分”,无法做“汇总”“统计”等聚合操作,因此选择此方式后不能添加聚合节点。点击定时任务-拉取增量数据可查看关于此类任务创建数据源中的详细说明
-
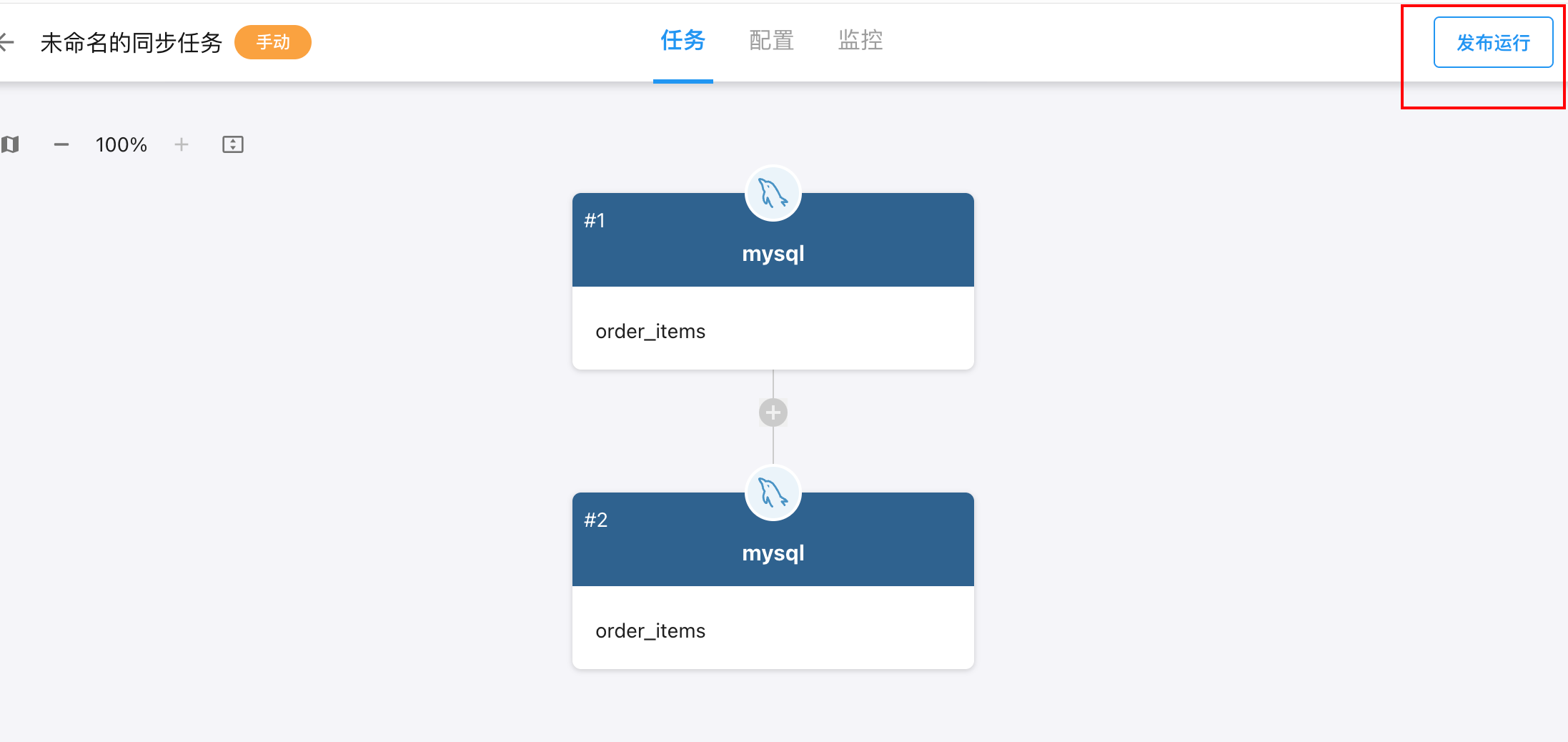
7.发布同步任务
完成以上配置后,点击任务画布右上角的 「发布运行」 或 「发布」 按钮,即可将任务生效。
-
手动任务: 点击「发布运行」后,即可将任务生效
-
定时任务: 点击「发布」,即开启定时任务,可点击「立即运行」当即运行任务
-
实时任务: 点击「发布」,立即进入实时监听状态,可重新手动暂停/停止任务
8.监控运行情况
“监控”页用于查看同步任务的运行情况,包括运行次数、运行耗时、读取与写入总量、历史运行记录、算力消耗等信息。通过此页面,用户可以了解任务是否正常运行、运行效率如何、是否出现异常。
该区域根据任务类型略有不同,但通常包含:
- 任务类型(手动 / 定时 / 实时)
- 累计运行时长
- 累计读取记录数
- 累�计写入记录数
字段说明:
| 字段 | 含义 | 典型用途 |
|---|---|---|
| 累计运行时长 | 任务自发布以来总的运行时长(实时任务持续增长) | 用于评估任务是否长期稳定运行 |
| 累计读取记录数 | 从数据源累计读取的记录数量 | 判断源表规模、增量数据量 |
| 累计写入记录数 | 写入到目的地表的累计记录数量 | 判断目标表增长情况 |
在执行同步任务时,某些操作会导致任务重新写入目标表中的全部数据。为避免数据重复、目标表结构不一致或数据污染,系统会在以下场景中提醒用户是否需要彻底清空目的地表数据。请根据业务情况谨慎确认。以下情况会触发提醒:
-
手动任务执行“重新运行”时
当用户对手动同步任务点击重新运行:
- 系统将在目标表写入新的整批数据;
- 若目标表内仍保留上一次同步的旧数据,可能导致重复或冲突。
因此,系统会提示用户是否需要清空目标表数据,以保证任务数据的一致性与正确性。
-
使用全量模式的定时任务
当数据源节点在配置中选择:“每次获取数据源的全量数据”
系统会在每次同步时拉取整个源表的数据。
若目标表不进行清空,将产生重复记录或产生错误累积。
因此,系统会提醒用户是否需要在同步前彻底删除现有目标数据。
-
任务更新后执行“重新发布”时
当任务处于 “有更新未发布” 状态,用户点击 “重新发布” 时:
-
新配置可能改变字段结构、数据逻辑或同步方式;
-
若目标表保留旧数据,可能出现字段不匹配、数据冲突等问题。
因此,系统会提示用户是否需要清空目的地表,以确保新版本任务的正确性。
-
• 同步的数据方向是多种方式的,既可以将 HAP工作表同步到数据库,也可以将外部数��据库同步到HAP工作表,更可以在外部数据库之间同步,比如将MySQL的数据同步到MongoDB数据库中。
• 选择HAP工作表时,只能选择到个人拥有者权限下的应用,其他应用是不可选择,表到表是不支持跨组织同步的
定时任务-拉取增量数据
当任务设置为 “每次拉取增量数据” 时,系统在每次同步时只会拉取新增或更新的记录,而不会删除目标表中已有的数据。
此模式适用于:持续新增数据、持续更新数据、需要保持“累积数据集”的任务。
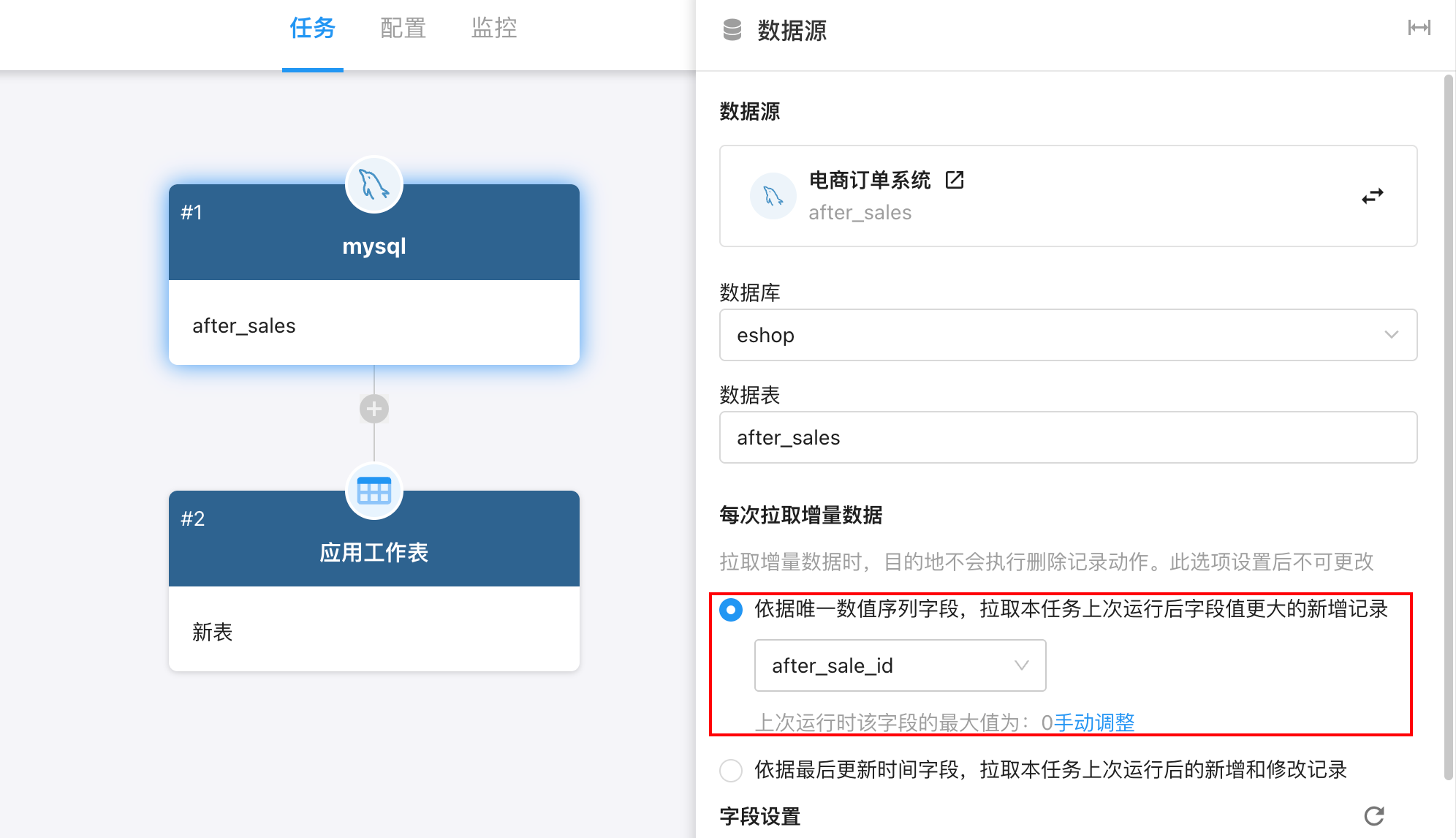
模式一:依据唯一数值序列字段拉取新增记录(适用于自增 ID)
系统会使用用户选择的“唯一数值序列字段”(通常是自增 ID,如:after_sale_id),判断哪些记录属于“上次运行之后新增的数据”。
哪些数据会同步:
-
系统会记住 上次成功运行时,该字段的最大值。 例如:after_sale_id 上次最大值 = 80
-
下次同步时,只会拉取 after_sale_id > 80 的新增记录。
-
“最大值”会在每次成功同步后自动更新。
字段要求:
-
必须是持续递增的数值字段(如自增 ID)
-
不能回退、不能乱序,否则会出现重复拉取或遗漏数据
用户操作:
- 用户可以点击 “手动调整” 修改当前记录的最大值,适用于修复异常情况(如误同步)。
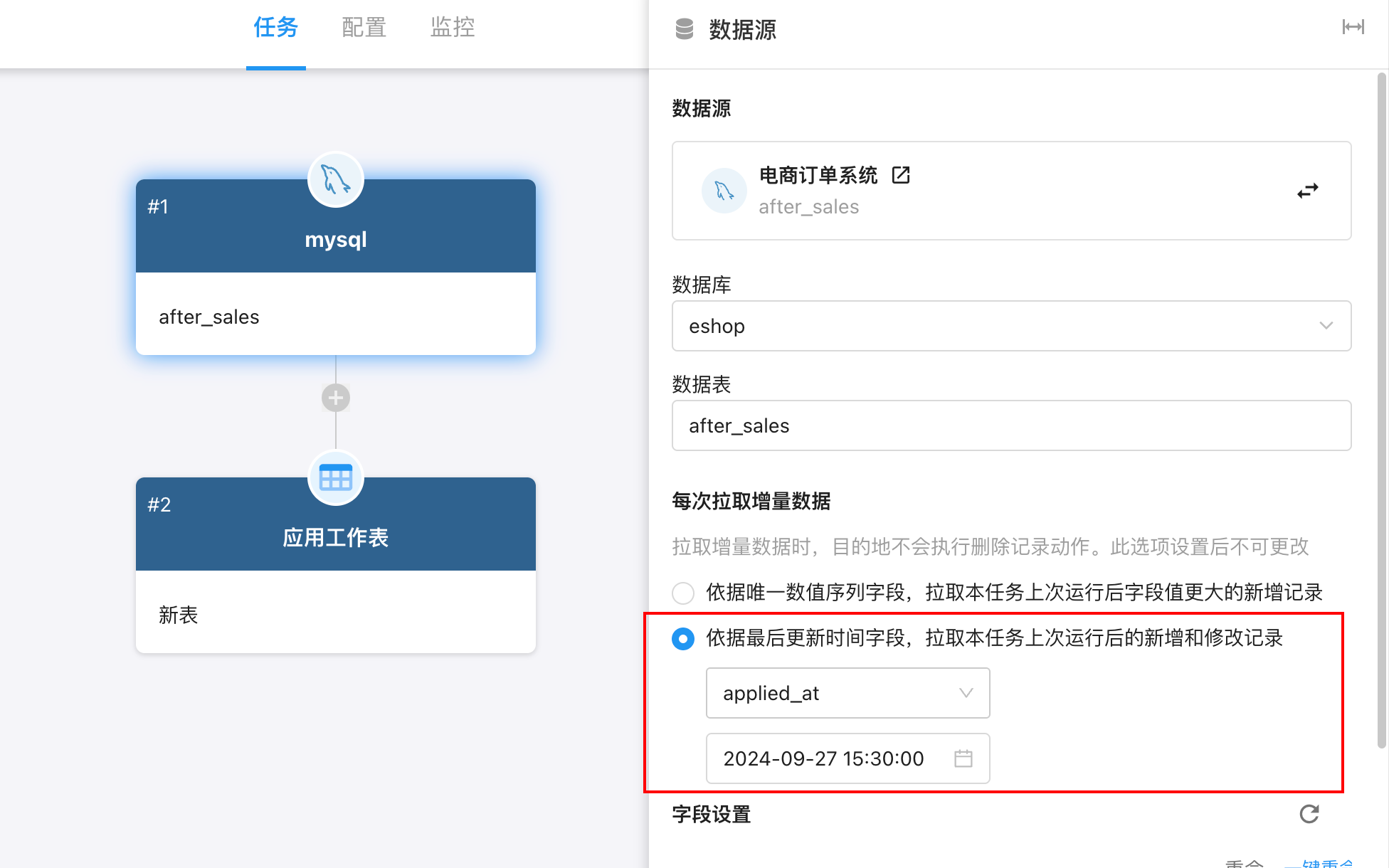
模式二:依据最后更新时间字段拉取新增 + 修改记录(适用于 update_at)
当数据有更新/修改行为时(例如 updated_at 字段发生变化),使用此模式更适合。
哪些数据会同步:
-
上次同步成功后,系统记录该字段的最新时间点
-
下次同步时,将拉取:
▪ 更新时间 > 上次执行时间 的新增记录
▪ 更新时间 > 上次执行时间 的修改记录
适用场景:
-
数据不是按自增 ID 产生,而是随时可能被修改
-
需要同步“更正过的数据”(例如售后状态更新、订单状态更新)
字段要求:
- 类型必须是 时间戳/日期时间字段
- 必须代表“记录最近一次��被修改的时间”
两种模式的对比
| 场景 | 推荐选择 | 原因 |
|---|---|---|
| 记录只会新增,不会修改 | 依据唯一数值序列字段 | 更快更稳定,避免重复拉取 |
| 记录频繁修改(如状态变更) | 依据最后更新时间字段 | 能同步变化过的数据 |
| 字段是连续自增 ID | 数值序列字段 | 最适合 |
| 字段不是递增的(如工单编号) | 更新时间字段 | 避免数据遗漏 |
不支持同步的字段类型
以下控件类型在同步任务中,作为源字段可读取,不支持写入(如表中标注“仅同步”,表示仅能从源读取,无法写入目的地):
| 序号 | 控件名称 | 控件类型编号 | 说明 |
|---|---|---|---|
| 1 | 大写金额 | 25 | — |
| 2 | 备注 | 10010 | — |
| 3 | 自由连接 | 21 | — |
| 4 | 嵌入 | 45 | — |
| 5 | 分割线 / 分段 | 22 | — |
| 6 | 标签页 | 52 | — |
| 7 | 关联记录 | 29 | 多条记录 |
| 8 | 他表字段 | 30 | 仅同步(不可写) |
| 9 | 签名 | 42 | — |
| 10 | 条码 | 47 | — |
| 11 | API 查询 | 49 | 查询按钮 |
| 12 | 文本识别 | 43 | — |
| 13 | �关联查询 | 51 | — |
工作表字段同步规则
在目的地为数据库时,支持同步以下工作表字段。以下字段为工作表内置字段,字段 ID 固定不可修改。
| 场景 | 推荐选择 | 原因 |
|---|---|---|
| 记录只会新增,不会修改 | 依据唯一数值序列字段 | 更快更稳定,避免重复拉取 |
| 记录频繁修改(如状态变更) | 依据最后更新时间字段 | 能同步变化过的数据 |
| 字段是连续自增 ID | 数值序列字段 | 最适合 |
| 字段不是递增的(如工单编号) | 更新时间字段 | 避免数据遗漏 |
任务管理
“同步任务列表”用于集中展示当前空间下的所有同步任务,包括手动任务、定时任务、实时任务及其运行情况。用户可以在此查看任务状态、执行历史,并进行发布、运行、暂停等操��作。此页面适用于管理和定位同步任务,是任务运维与监控的入口。
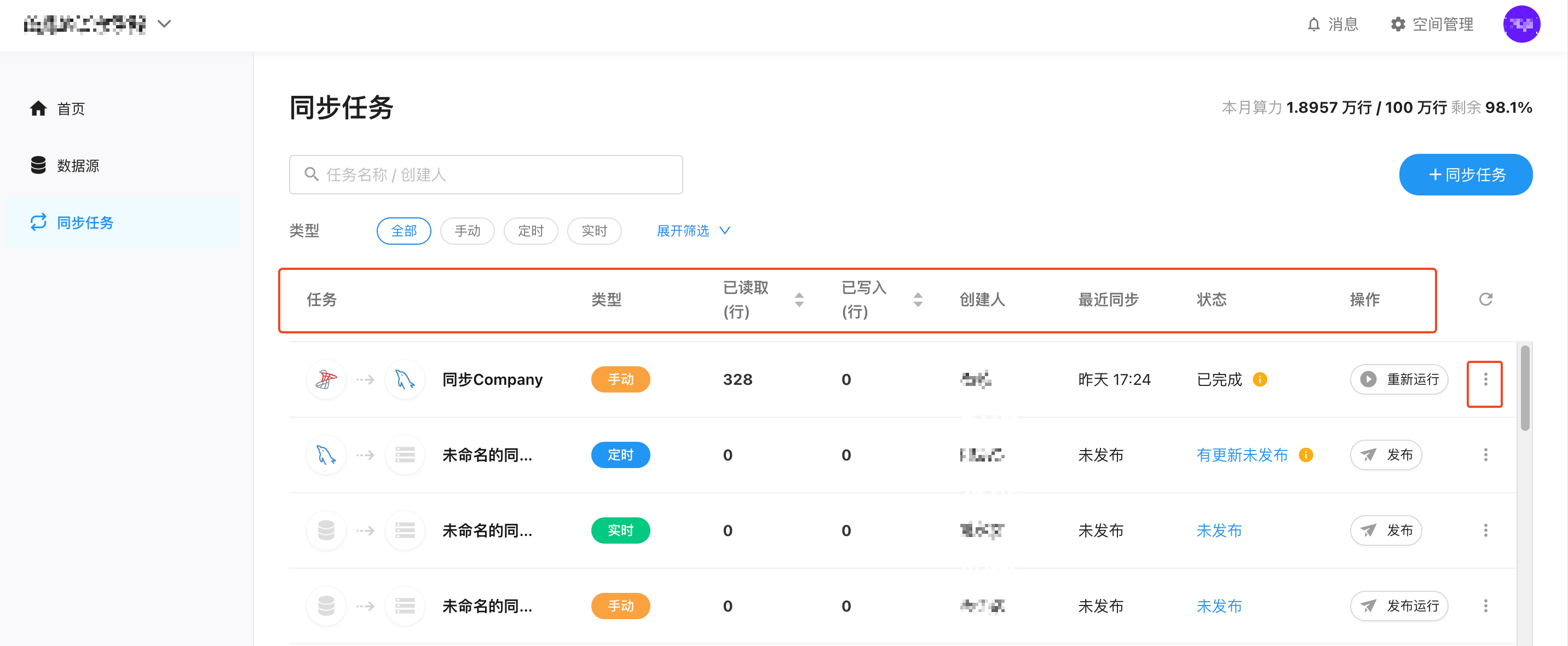
页面结构说明:
- 搜索框:支持按任务名称关键字搜索
- 任务类型筛选:可切换“全部 / 手动 / 定时 / 实时”,用于过滤不同类型的任务
- 展开更多筛选器:可按状态、数据源,筛选目标任务
- 算力用量提示:展示本月已使用与剩余的同步算力(行数)
任务列表字段说明:
任务列表按表格形式展示以下信息:
| 列名 | 说明 |
|---|---|
| 任务 | 同步任务名称 |
| 类型 | 任务类型(手动 / 定时 / 实时) |
| 已读取(行) | 最近一次同步时从源端读取的数据量,可点击表头进行升降排序 |
| 已写入(行) | 最近一次同步时成功写入目标的数据量,可点击表头进行升降排序 |
| 创建人 | 任务创建者 |
| 最近同步 | 最近一次运行的时间(若未运行则显示“未同步”或“未发布”) |
| 状态 | 当前任务状态,如:未发布、未开启、有更新未发布、已完成、运行中、已暂停、已停止等 |
| 操作 | 对该任务进行执行类操作,如“发布运行 / 重新运行 / 发布 / 暂停同步”等 |
可执行操作说明:
所有任务类型均支持以下基础操作:
-
重命名
-
复制任务(弹窗输入新名称)
-
查看监控(查看历史执行记录)(未发布任务除外)
-
删除任务(弹出删除确认)
除以上操作,对不同任务类型及不同状态的任务可执行操作如下:
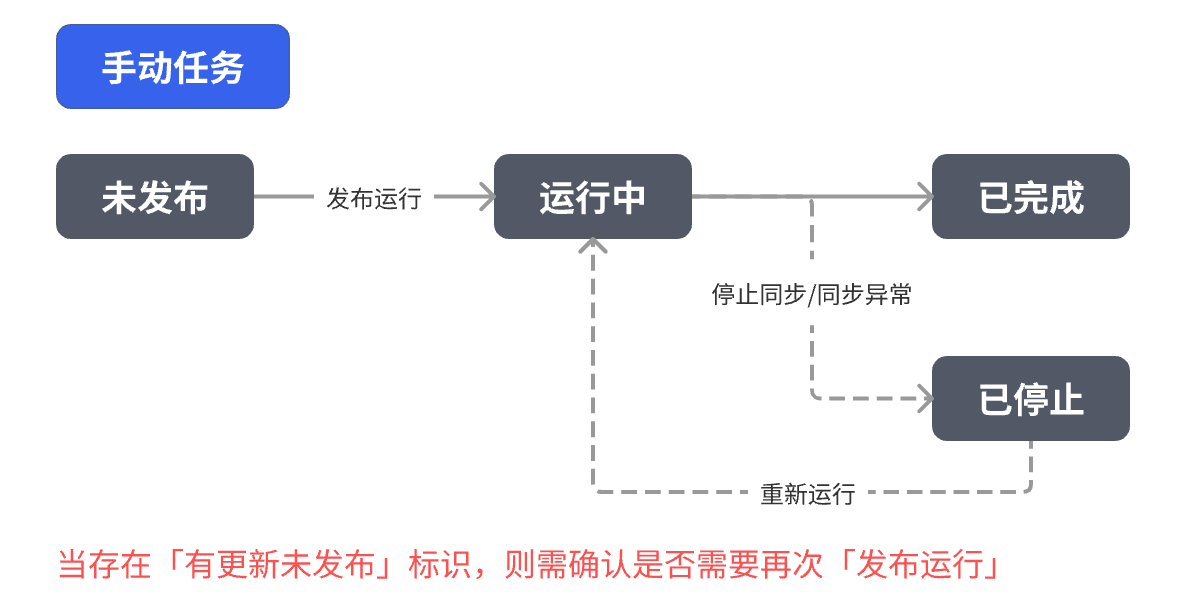 | 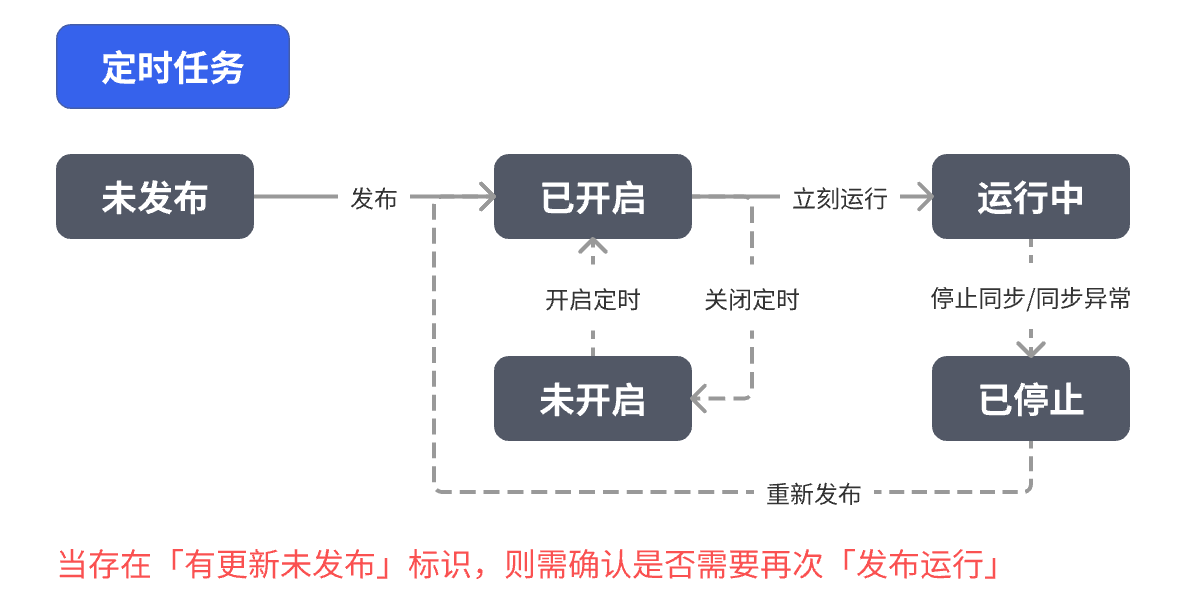 | 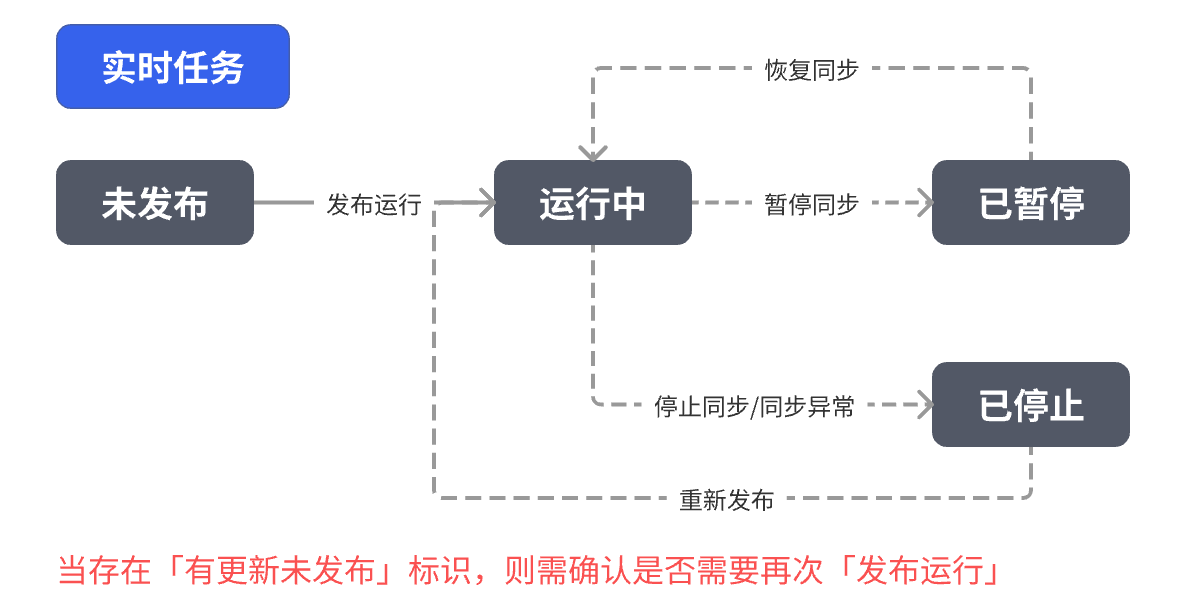 |
常见状态说明:
| 状态 | 含义 |
|---|---|
| 未发布 | 配置已保存但尚未生效 |
| 有更新未发布 | 修改了任务配置但未重新发布 |
| 已完成 | 手动任务同步已成功完成 |
| 运行中 | 任务正在稳定运行 |
| 已停止 | 任务被人工或系统中断 |
| 已暂停 | 实时任务被人工暂停 |
| 未开启 | 定时任务关闭定时 |
Was this document helpful?